Eine Datenbank ist eine Menge von Daten, die gruppiert werden und in unterschiedlicher Art und Weise in Beziehung zueinander stehen können. Sie sollen in der Regel für verschiedene Benutzer und Aufgabenstellungen aufbereitet, analysiert werden und so weiter. Wir können von einer abstrakten Miniaturwelt sprechen, die einen relevanten, auf ein Problemfeld reduzierten, Ausschnitt der realen Welt abbildet. Wir haben uns daher mit der Theorie zu Entwurf und Implementierung relationaler Datenbanken auseinanderzusetzen.
In einer Datenbank zur Abbildung einer Universitätsbibliothek werden sicherlich Personendaten, wie Vor- und Nachnamen, Wohnorte und Matrikelnummern gespeichert, die Größe und Haarfarbe der Studierenden werden jedoch nicht von Interesse sein.
Selbst wenn offensichtlich nicht alle Informationen der realen Welt von Interesse sind, weil sie keine Relevanz für die abzubildende Problemstellung besitzen, kann die Anzahl der abzubildenden Objekte, die Vielzahl interessierender Eigenschaften und deren Beziehungen zueinander, schnell sehr komplex werden.
Die Problematik der Komplexität und des damit verbundenen Aufwands ist nicht neu. Die Softwareentwicklung hat verschiedene Konzepte entwickelt, um dem Problem der Komplexität Herr zu werden, den Aufwand für die Entwicklung von Software zu reduzieren und im Sinne eines Qualitätsmanagements Entwicklungsfehler zu vermeiden. Für den Entwurf und den Aufbau von Datenbanken, wurden ebenso Konzepte entwickelt.
3-Ebenen-Modell
Das amerikanische Normungsgremium ANSI/SPARC (American National Standards Institute/Standards Planning and Requirements Committee) stellte bereits 1975 das 3-Ebenen-Modell (vgl. https://de.wikipedia.org/wiki/ANSI-SPARC-Architektur) für den Aufbau relationaler Datenbanksysteme vor. Wie der Name verrät, beinhaltet das Modell drei Ebenen:
- externe Ebene,
- konzeptionelle Ebene und
- interne Ebene.
Die Ebenen besitzen klar abgegrenzte Inhalte und Aufgaben. Auf Basis dieses Modells ist es möglich, Datenbanken zu entwerfen und zu implementieren, ohne stets die gesamte Problematik und Komplexität vor Augen zu müssen.
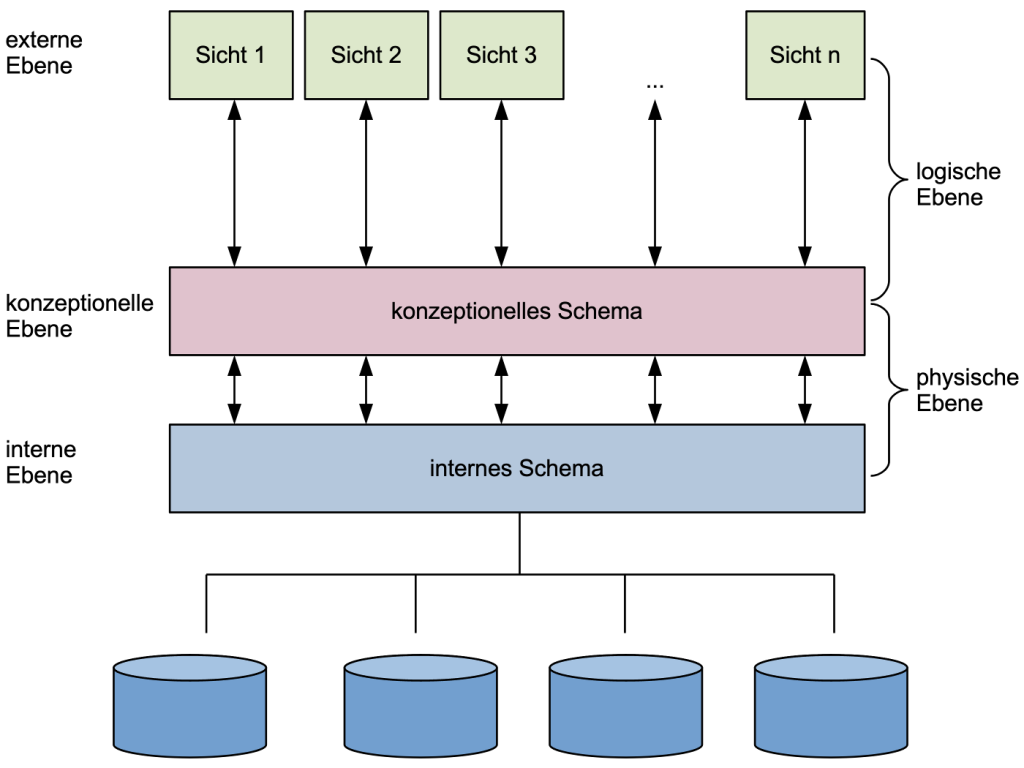
Auf der internen Ebene werden die physischen Aspekte der Datenspeicherung beziehungsweise des Datenzugriffs beschrieben. Hierzu zählen auch die Zugriffsberechtigungen, Such- und Sortierverfahren und anderes mehr.
Die externe Ebene beschreibt die Benutzersicht auf die Daten. Dabei können gleiche Daten für unterschiedliche Benutzer(gruppen) unterschiedlich aufbereitet sein. Auch können nicht alle Benutzer alle Daten gleichsam einsehen, erfassen und/oder modifizieren. Während die Mitarbeiter der Personalabteilung die Löhne und Gehälter in einem Unternehmen einsehen und bearbeiten können, ist dies den Mitarbeitern der Einkaufsabteilung in der Regel verwehrt. Deren Leiter mag aber durchaus Einsicht in die aktuellen Gehälter seiner Mitarbeiterinnen und Mitarbeiter haben, ohne diese jedoch eigenständig verändern zu können.
Interne und externe Ebene werden durch die konzeptionelle Ebene verbunden. Sie bildet die Schnittstelle, die den logischen, von Benutzern und physischen Belangen unabhängigen, Blick auf die Daten der Datenbank gewährt. Hier werden die Tabellen und dazugehörigen Zugriffspfade verwaltet.
Nahezu alle heutigen RDBMS (Relational Database Management Systems) implementieren das 3-Ebenen-Modell. Server-basierte RDBMS abstrahieren darüber hinaus auch noch von den Details der Kommunikationen von Programmen in einem Computernetzwerk.
Über eine spezielle Programmiersprache, genannt SQL, kommunizieren Sie mit einem RDBMS. Damit weisen Sie die Software an, welche Aktionen Sie auszuführen gedenken.
Entity-Relationship-Modell
Ein Entity-Relationship-Modell, kurz ER-Modell, beschreibt die Objekte (Entities) unserer abstrakten Datenbankwelt und ihre Beziehungen (Relationships) zueinander. Die ER-Modellierung geht auf Peter Pin-Shan Chen, chinesisch: Chen Pin-Shan (陳品山), einem taiwanesischen Informatiker, zurück, der als Professor in den USA lehrt und es 1976 für die Datenanalyse entwickelte und publizierte (vgl. https://de.wikipedia.org/wiki/Peter_Chen).
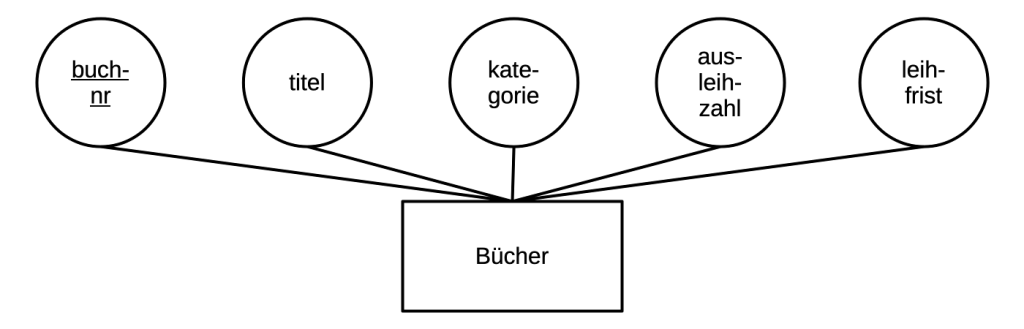
Objekte sind eindeutig identifizierbar, wie beispielsweise ein einzelnes Buchexemplar in einer Universitätsbibliothek. Objekte können auch abstrakt sein, wie zum Beispiel ein Verleihvorgang. Alle Objekte lassen sich durch Attribute beschrieben. Klassisch werden Objekte im einem ER-Diagramm, der grafischen Darstellung eines ER-Modells, durch Rechtecke dargestellt. Attribute werden durch Ellipsen oder Kreise dargestellt. Identifikationsschlüsselattribute werden unterstrichen.
Zwischen den Objekten können Beziehungen bestehen. Beziehungen werden klassisch mittels einer Raute dargestellt. Auch Beziehungen sind durch Attribute näher beschreibbar.
Die Verbindungen erläutern die Beziehung. Hier: Autoren schreiben Bücher.

Präziser wird eine Beziehung dokumentiert, wenn wir Sie um Kardinalitäten ergänzen.
- Eine vertikale Linie zeigt an, dass ein Element der entsprechenden Menge in die Beziehung involviert ist.
- Eine doppelt vertikale Linie zeigt an, dass genau ein Element der entsprechenden Menge in die Beziehung involviert ist.
- Ein Kreis zeigt an, dass kein Element der entsprechenden Menge in die Beziehung involviert sein muss.
- Ein „Krähenfuß“ zeigt an, dass mehrere Elemente der entsprechenden Menge in die Beziehung involviert sein können.
Ein Autor kann mehrere Bücher geschrieben haben, gegebenenfalls aber auch keines. Ein Buch hat mindestens einen Autor, kann aber auch von mehreren Autoren verfasst sein.
Im ER-Diagramm stellen wir diesen Sachverhalt wie folgt dar:
Es können letztlich drei Grundformen von Beziehungen unterschieden werden. 1:1, 1:n, m:n. Die Zahlen drücken aus, wie viele Datensätze einer Tabelle mit einer anderen Tabelle in Beziehung stehen (können).
Hinweis: Diese Grundbeziehungen sind anhand der oben genannten Kardinalitäten weiter spezifizierbar. So kann eine 1:1-Beziehung, um ein Beispiel herauszugreifen, auch auf einer Seite eine Null beinhalten oder eben auch genau eins bedeuten.
Sehen wir uns zu den Beziehungstypen einige Beispiele an, wie wir sie in der Praxis häufig antreffen, um die Beziehungstypen zu klären:
| Beziehung | Bedeutung |
|---|---|
| 1:1 | Ehe: ein Mann hat eine Frau und eine Frau hat einen Mann. Das gilt zumindest in unserem Kulturkreis. In anderen Kulturkreisen kann die Ehe auch eine 1:n-Beziehung sein. Ein Mann kann dort mehrere Frauen haben. |
| 1:n | Ein Kind hat eine Mutter, jede Mutter kann mehrere Kinder haben. |
| m:n | Jeder Mitarbeiter kann in mehreren Projekten mitarbeiten. In jedes Projekt können mehrere Mitarbeiter involviert sein. |
m:n-Beziehungen sind durch je zwei 1:n-Beziehungen zu implementieren. Es werden also pro m:n-Beziehung drei Tabellen zu deren Abbildung benötigt.
Normalisierung
Um Unvollständigkeiten, unerwünschte Redundanzen und Inkonsistenzen in der Datenbankstruktur beziehungsweise den Datenbankinhalten zu vermeiden, werden Tabellen und Attribute in eine mathematisch eindeutige Form gebracht. Hierbei geht man gewöhnlich schrittweise vor. Die Ergebnisse der Zwischenschritte werden 1. bis 5. Normalform genannt. Letztere bildet das Ziel des sogenannten Normalisierungsprozesses. In der Praxis werden meistens lediglich die ersten drei Normalformen verwendet. Die letzten beiden haben eher akademischen Charakter und werden deshalb im Weiteren nicht betrachtet.
Zur Illustration der einzelnen Normalisierungsschritte soll ein Beispiel aus einem Schulungsbetrieb dienen. Dozenten geben an unterschiedlichen Standorten Kurse für Studierende. In einer Datenbank soll festgehalten werden, welcher Dozent aus welchem Wohnort, welchen Kurs, in welchem Raum gibt und wie viele Studenten den jeweiligen Kurs besuchen. Bei drei Dozenten und fünf Kursen könnte eine nicht normalisierte Darstellung der Tabelle dozenten etwa wie folgt aussehen. Für das Zutreffen von Dozenten und Kursen wurden Kreuze verwendet. Diese Art von Tabellen finden sich häufig als Übersichten an Wänden von Lehrerzimmern wieder.
do1 | do2 | do3 | ku1 | ku2 | ku3 | ku4 | ku5 | teiln | plz | ort | raum |
|---|---|---|---|---|---|---|---|---|---|---|---|
| x | x | 20 | 49090 | Osnabrück | a | ||||||
| x | x | 34 | 49090 | Osnabrück | b | ||||||
| x | x | 19 | 49090 | Osnabrück | c | ||||||
| x | x | 20 | 49124 | Georgsmarienhütte | e | ||||||
| x | x | 19 | 49124 | Georgsmarienhütte | c | ||||||
| x | x | 25 | 49124 | Georgsmarienhütte | d | ||||||
| x | x | 34 | 49124 | Georgsmarienhütte | b |
do# ist der jeweilige Dozent, ku# bezeichnet jeweils einen Kurs und teiln ist die Anzahl der angemeldeten Teilnehmer. Diese Tabellenmodellierung ist jedoch nicht ideal. Für jeden neuen Dozenten oder Kurs muss die Tabellenstruktur geändert werden. Deshalb besagt die erste Normalisierungsregel: Wiederholungsgruppen sind zusammenzufassen. Wiederholungsgruppen sind in diesem Beispiel die verschiedenen Dozenten sowie die Kurse.
doznr | kursnr | teiln | plz | ort | raum |
|---|---|---|---|---|---|
| 1 | 1 | 20 | 49090 | Osnabrück | a |
| 1 | 2 | 34 | 49090 | Osnabrück | b |
| 1 | 3 | 19 | 49090 | Osnabrück | c |
| 2 | 1 | 20 | 49124 | Georgsmarienhütte | e |
| 2 | 3 | 19 | 49124 | Georgsmarienhütte | c |
| 2 | 5 | 25 | 49124 | Georgsmarienhütte | d |
| 3 | 2 | 34 | 49124 | Georgsmarienhütte | b |
Die Tabelle dozenten erfüllt jetzt die 1. Normalform in Bezug auf unsere Problemstellung – alle Wiederholungsgruppen sind eliminiert.
Die 2. Normalform verlangt nun, in einem weiteren Schritt, nach zusammengesetzten Schlüsseln zu suchen. Alle zusammengesetzten Schlüssel haben eine eigene Tabelle zu bilden. Die von einfachen Schlüsseln abhängigen Merkmale sind ebenfalls in eine eigene Tabelle zu schreiben.
kursnr | teiln |
|---|---|
| 1 | 20 |
| 2 | 34 |
| 3 | 19 |
| 5 | 25 |
Offensichtlich hängen die Teilnehmerzahlen mit den Kursen zusammen. Wir spendieren diesem Sachverhalt deshalb eine eigene Tabelle. Der Wohnort nebst Postleitzahl ist jeweils vom Dozenten abhängig. Auch dies führt zu der Erkenntnis, eine Tabelle zur Abbildung dieses Sachverhalts kreieren zu müssen, um die 2. Normalform zu erreichen.
doznr | plz | ort |
|---|---|---|
| 1 | 49090 | Osnabrück |
| 2 | 49124 | Georgsmarienhütte |
| 3 | 49124 | Georgsmarienhütte |
Dozenten und Kurse bilden einen zusammengesetzten Schlüssel, von dem der Raum abhängt. Der Sachverhalt bekommt also ebenfalls eine eigene Tabelle.
doznr | kursnr | raum |
|---|---|---|
| 1 | 1 | a |
| 1 | 2 | b |
| 1 | 3 | c |
| 2 | 1 | e |
| 2 | 3 | c |
| 2 | 5 | d |
| 3 | 2 | b |
Aus einer Tabelle sind jetzt drei Tabellen geworden. Beachte: Jede höhere Normalform erfüllt auch stets die Kriterien der vorhergehenden Normalform. Die 2. Normalform erfüllt also auch immer die Bedingungen der 1. Normalform. Gleiches gilt dann analog für die folgende 3. Normalform sowie auch die 4. und 5. Normalform, die wir hier jedoch nicht betrachten werden.
In der 3. Normalform müssen alle Nicht-Schlüssel-Attribute direkt vom Schlüssel abhängig sein. Es dürfen keine transitiven Nicht-Schlüssel-Attribute in den Tabellen existieren.
| Transitivität bedeutet: | \((A \Rightarrow B \Rightarrow C) \Leftrightarrow (A \Rightarrow C)\) |
| Direkt abhängig bedeutet: | \((A \Rightarrow B \Rightarrow C) \Leftrightarrow (C \Rightarrow A\)) |
Prüfen wir dies für die Tabelle dozenten:
(doznr \(\Rightarrow\) plz \(\Rightarrow\) ort) \(\Leftrightarrow\) (doznr \(\Rightarrow\) ort) |
Transitivität: JA |
(doznr \(\Rightarrow\) plz \(\Rightarrow\) ort) \(\Leftrightarrow\) (ort \(\Rightarrow\) doznr) |
Direkte Abhängigkeit: NEIN |
Wenn doznr und ort direkt abhängig wären, müsste
(3 \(\Rightarrow\) 49124 \(\Rightarrow\) Georgsmarienhütte)
\(\Leftrightarrow\) (Georgsmarienhütte \(\Rightarrow\) 3)
gelten. Das tut es jedoch nicht, weil auch Dozent 2 aus Georgsmarienhütte kommt. Deshalb ist die Tabelle dozenten nochmals aufzuteilen. - Die anderen Tabellen erfüllen bereits die 3. Normalform, bleiben also unverändert.
doznr | plz |
|---|---|
| 1 | 49090 |
| 2 | 49124 |
| 3 | 49124 |
plz | ort |
|---|---|
| 49090 | Osnabrück |
| 49124 | Georgsmarienhütte |
Anmerkung: Umgangssprachlich kann man den Sinn und Zweck der Normalformen auch so formulieren, ein Tabellendesign zu entwerfen, bei welchem lediglich Redundanzen in den Schlüsselattributen auftreten. Alle weiteren Redundanzen werden durch die Normalisierung eliminiert.
SQL - Structured Query Language
SQL steht für Structured Query Language, was soviel wie „strukturierte Abfragesprache“ bedeutet. Trotz des Namens sind die Fähigkeiten von SQL nicht auf bloße Abfragen beschränkt. Mittels SQL können ebenso Datenstrukturen erzeugt und modifiziert sowie Daten verwaltet werden.
SQL ist 1986 als ANSI-Standard verabschiedet worden. Trotz dieses Standards haben die verschiedenen Hersteller von Datenbankmanagementsystemen eigene Erweiterungen implementiert. Diese sollen vorhandene wie vermeintliche Unzulänglichkeiten von SQL beseitigen. Es empfiehlt sich daher grundsätzlich ein Blick in die jeweilige Dokumentation, will man ein bestimmtes Datenbankmanagementsystem optimal nutzen. In der Regel implementieren alle Datenbankmanagementsysteme nur eine Untermenge des SQL-Standards. In Verbindung mit den jeweils eigenen Erweiterungen ergeben sich so die Unterschiede in deren Handhabung. Dennoch sind die Gemeinsamkeiten so groß, dass das Datenbank- und SQL-Wissen, welches in Bezug auf ein bestimmtes Produkt erworben wurde, auch auf andere Systeme leicht übertragen werden kann.
Um SQL in den Reigen der verschiedenen Programmiersprachen einzuordnen, denn um eine solche handelt es sich letztlich, mag die folgende Auflistung hilfreich sein, die in bekannter Weise Sprachen nach Generationen unterteilt. Die Gliederung ist historisch begründet und spiegelt die Fortschritte der IT bezüglich der Programmierung oder „wie sage ich dem Computer, was er tun soll“ wider.
- 1. Generation: Maschinencode (krude Folgen von Nullen und Einsen, anfänglich ein Haufen von Ein-/Aus-Schaltern, die in ihrer Gesamtheit ein Programm darstell(t)en)
- 2. Generation: Assembler (Zusammenfassung von Nullen und Einsen unter dem Dach eines einigermaßen verständlichen Synonyms, um das Ganze für den Menschen leichter lesbar zu machen –- Beispiel:
add AX,42, um zum Inhalt des RegistersAXden Wert 42 zu addieren) - 3. Generation: Problemorientierte Sprachen (C, Java, Python, … –- üblicherweise an die englische Sprache angelehnte Syntax, bei der sich hinter jedem Befehl in der jeweiligen Sprache eine ganze Reihe von Assemblerbefehlen verbirgt. Beispiel: Der
printf-Befehl in C würde, in Assembler ausgedrückt, locker eine DIN-A4-Seite und mehr füllen, wollte man den Code ausdrucken) - 4. Generation: Anwendersprachen (SQL, Natural, … –- SQL lernen Sie jetzt kennen)
- 5. Generation: logische und funktionale Sprachen (Lisp, Prolog, Miranda, … –- nur für Sonderlinge und wissenschaftliche Mitarbeiter an Hochschulen, können wir hier vergessen)
SQL zählt zu den sogenannten Anwendersprachen. Diese Klassifikation sagt noch nichts über das Wesen der Sprache aus. SQL ist eine logische, mengenorientierte, nicht-prozedurale Sprache. Für Kenner einer gewöhnlichen Programmiersprache, womit eine aus der 3. Generation gemeint ist, mag SQL daher etwas gewöhnungsbedürftig sein. Die wesentlichen Merkmale der problemorientierten Sprachen sind Datenstrukturen (Variablen, Datentypen) und Kontrollstrukturen (Sequenz, Verzweigung/Fallunterscheidung, Wiederholung), die aber SQL gerade nicht anbietet - im Rahmen ihrer individuellen Spracherweiterungen hat dies dennoch jeder mir bekannte Datenbankhersteller implementiert. PostgreSQL bildet hier keine Ausnahme. An die Stelle konkreter Einzelanweisungen, die vom Rechner Schritt für Schritt abgearbeitet werden und am Ende (hoffentlich) das gewünschte Ergebnis erzeugen, tritt eine logische Beschreibung dessen, was als Resultat der Verarbeitung herauskommen soll. Wie dies im Einzelnen genau geschieht, ist nicht Sache des Anwenders, sondern des SQL-Interpreters des Datenbankmanagementsystems. Diese höhere Abstraktionsebene erklärt den Generationssprung von den gewöhnlichen Sprachen zu SQL.
| 3GL (Pseudocode) | 4GL (SQL) |
|---|---|
open(kunden);
while (not eof(kunden)) {
read(kunden, kunde);
print(kunde);
}
close(kunden);
|
SELECT * FROM kunden; |
Bei einer 3GL-Sprache, einer Sprache der dritten Generation, ist das Öffnen der Datei mit den Kundendaten sowie das abschließende Schließen der Datei explizit anzugeben. Dazwischen findet die eigentliche Datenverarbeitung statt.
In SQL werden diese lästigen Details, wie im Einzelnen vorzugehen ist, vom Anwender ferngehalten. Man sagt einfach, ins Deutsche übersetzt: „Zeige mir alle Datensätze aus der Tabelle kunden!“
Ein wichtiger Punkt, den man im Hinterkopf behalten sollte, ist, dass SQL keine vollständige Programmiersprache ist. Das heißt, SQL ist nicht universell für alle nur erdenklichen Programmierprobleme einsetzbar. SQL beschränkt sich auf die Handhabung von relationalen Datenbanken. Diese Einschränkungen sind aber weder ein Versehen, weil man es bei der Sprachdefinition vergessen hat, noch ein Mangel, welcher der Sprache anhaftet. Die Sprache wurde von Anfang an so konzipiert, dass sie in andere Programmiersprachen eingebettet werden kann (Embedded SQL). Der ANSI-SQL-Standard selbst schreibt einen Mechanismus vorschreibt vor, wie SQL in eine problemorientierte Sprache, wie beispielsweise C, Java oder Python, zu integrieren ist.
SQL-Befehle lassen sich in drei Klassen einteilen:
- DDL-Befehle: (Data Definition Language) erzeugen (Datenbanken, Tabellen, Sichten, Indizes und so weiter, verändern oder löschen sie.
- DCL-Befehle: (Data Control Language) dienen der Administration von Benutzern/Benutzergruppen und deren Zugriffsrechten auf die verschiedenen Datenbankobjekte.
- DML-Befehle: (Data Manipulation Language) werden für Abfragen sowie für das Einfügen, Ändern oder Löschen von Dateninhalten verwendet.
| DDL | DCL | DML |
|---|---|---|
CREATE | GRANT | SELECT |
| (Erzeugen eines Objekts) | (Rechte gewähren) | (Daten abfragen) |
ALTER | REVOKE | INSERT |
| (Objekte ändern) | (Rechte entziehen) | (Daten einfügen) |
DROP | DELETE |
|
| (Objekte löschen) | (Daten löschen) | |
RENAME | UPDATE |
|
| (Objekte umbenennen) | (Daten ändern) |