Nur mit einer Tabelle hantieren zu können, wie wir es bisher getan haben, ist langweilig. Zudem haben Sie in Kapitel „Entwurf und Implementierung“ gelernt, dass mithilfe der Normalisierung die Daten in einer relationalen Datenbank so auf verschiedene Tabellen verteilt werden, dass sich mögliche Redundanzen (weitestgehend) auf Schlüsselattribute beschränken. Die dahinter stehende Idee war/ist es, ein Datenmodell zu wählen, welches der Integrität der Daten einer Datenbank förderlich ist. Damit geht in der Regel einher, Daten, wenn wir sie abfragen wollen, wieder „zusammensetzen“ zu müssen. Wir benötigen daher oftmals mehr als nur eine Tabelle in einer Abfrage, um die interessierenden Daten vollständig anzuzeigen. Z.B. steht in der Tabelle der geleisteten Zahlungen lediglich ein Verweis auf den Kunden, der diese jeweils geleistet hat, um bei unserer Beispieldatenbank zu bleiben. Wir müssen ihn in einer verwiesenen Tabelle nachsehen. Wenn wir wissen wollen, welche Schauspieler in einem Film mitgewirkt haben, so müssen wir auch das in anderen Tabellen nachschlagen.
Kartesisches Produkt
Die einfachste Möglichkeit, mehrere Tabellen in einer Abfrage zu nutzen, ist es, diese Tabellen in der FROM-Klausel zu notieren. Damit ist es jedoch nicht getan, wie Sie gleich sehen werden.
|
1 2 3 4 5 6 7 |
SELECT payment_id , amount , first_name , last_name FROM payment , customer; |
Diese Abfrage liefert 9.613.351 Datensätze. Das ist nicht das, was wir erwarten. Die Anzahl der Zahlungen beläuft sich gerade auf 16.49 Datensätze. Wenn wir die darin enthaltene Kundennummer (customer_id) auflösen, Sie durch den Vor- und Nachnamen in der Anzeige ersetzen wollen, sollte sich die Anzahl der zurückgegebenen Datensätze nicht erhöhen. Es sollten 16.049 Datensätze sein.
Noch „verrückter“ wird es, wenn wir statt der expliziten Spaltenaufzählung einen Asterisk verwenden. Dann erhalten wir nicht nur die wahnsinnig große Anzahl an Datensätzen zurück, wir erhalten auch 16 Spalten. Die Spalte customer_id wird doppelt ausgegeben.
Schauen Sie sich nochmals die vollständigen Tabellen payment und customer an. In der Zahlungstabelle sind, wie schon gesagt, 16.049 Datensätze enthalten. Zudem haben wir 599 Kunden. Die 9.613.351 ergibt sich als Produkt dieser Datensatzanzahlen. Und die Anzahl der Spalten, wenn wir den Asterisk zur Spaltenauswahl verwenden, ergibt sich als Summe aus den 6 Spalten der Zahlungstabelle und den 10 Spalten der Kundentabelle.
Notieren wir in einem SELECTStatement die zu involvierenden Tabellen einfach als Liste hinter FROM, so bildet SQL das sogenannte Kreuzprodukt. SQL verknüpft jeden Datensatz der einen Tabelle mit jedem Datensatz der anderen Tabelle. Dabei ist es SQL egal, dass Sie eigentlich über das Attribut customer_id hätten verknüpfen wollen. So haben wir es im ER-Diagramm, Kapitel „Beispieldatenbank: DVD-Verleih“, dargestellt.
SQL schert sich nicht, um das was wir wollen, wir müssen es SQL mitteilen. Tun wir es nicht, wird ein Kreuzprodukt generiert. Für dieses gilt:
Seien A und B zwei Tabellen. Tabelle A habe zA Zeilen und sA Spalten. Tabelle B habe zB Zeilen und sB Spalten. Dann hat das Ergebnis einer „unbedingten“ Verknüpfung die Dimension von zA mal zB Zeilen und sA plus sB Spalten.
In längst vergangenen Tagen, wurde SQL das zu verwendende Verknüpfungskriterium in der WHERE-Klausel mitgeteilt.
|
1 2 3 4 5 6 7 8 |
SELECT payment_id , amount , first_name , last_name FROM payment , customer WHERE payment.customer_id = customer.customer_id; |
Toll – jetzt verknüpft SQL die beiden Tabellen so, wie wir das erwarten. Wir müssen SQL explizit mitteilen, wie wir Tabellen in einer Abfrage sinnig verknüpfen wollen. An der Spaltenanzahl, wenn wir den Asterisk verwenden, ändert das natürlich nichts. Das ist aber auch ok. Der Asterisk steht für „alle Spalten“. Die gibt SQL auch brav aus.
In der WHERE-Klausel ist Ihnen sicherlich aufgefallen, dass vor den zu verknüpfenden Attributen die Tabellennamen notiert sind. Das ist eine sogenannte Qualifizierung. Ohne Angabe des Tabellennamens vor den Attributbezeichnern weiß SQL nicht, auf welche Tabelle wir uns jeweils beziehen. Wir wollen die Datensätze der Zahlungstabelle mit nur jeweils dem Datensatz der Kundentabelle verknüpfen, bei dem die Kundennummer in der Zahlungstabelle mit der Kundennummer in der Kundentabelle übereinstimmen.
Immer die vollen Tabellennamen schreiben zu müssen, mag dem einen oder anderen zu aufwendig sein. Wir werden uns daher gleich Tabellenaliase ansehen. – Ich möchte jedoch erwähnen, dass deren Verwendung in manchen Projekten der realen Welt unerwünscht sind. Bei vielen Tabellen können solche Abkürzungen unübersichtlich werden. Mancher Projektleiter fordert daher, stets die vollen Tabellennamen zur Qualifikation zu verwenden, Schreibaufwand hin oder her.
Der wesentlich Kritikpunkt an dem, wie wir unsere Tabellen verknüpft haben, ist aber der, eine Datensatzauswahlbedingung als Verknüpfungskriterium genutzt zu haben. In längst vergangenen Zeiten war dies das Mittel der Wahl. Irgendwann, mittlerweile auch schon lange her, hat man in SQL aber das Schlüsselwort JOIN eingeführt. Darüber werden Tabellen verknüpft. Die WHERE-Klausel bleibt dann allein der Datensatzauswahl erhalten. Wir haben eine saubere Trennung zwischen Tabellenverknüpfung und Datensatzauswahl. – Sehen wir uns das im Folgenden an. Vorher aber kurz zu den Aliasbezeichnern für Tabellen.
Aliasbezeichner für Tabellen
Ein Tabellenalias ist, wie bei einem Alias üblich, ein alternativer Bezeichner für das Original. Im Zusammenhang mit SQL geht es darum, sich Schreibarbeit zu ersparen. Die Syntax ist analog zu der von Aliasbezeichnern für Spalten. Das AS ist optional. M.E. erleichtert es aber die Lesbarkeit des Codes.
|
1 2 3 4 5 6 7 8 9 |
SELECT payment_id , amount , c.customer_id , first_name , last_name FROM payment AS p , customer AS c WHERE p.customer_id = c.customer_id; |
Für die Tabelle payment wurde hier der Alias p und für customer der Aliasbezeichner c definiert. Einmal definiert muss der Aliasbezeichner für die Qualifikation der Spalten, so sie nicht eindeutig einer Tabelle zuzuordnen sind, verwendet werden. Ich habe hier in der Spaltenauswahl die customer_id hinzugenommen, um zu zeigen, auch hier qualifizieren zu müssen, wenn wir eine nicht eindeutig bezeichnete Spalte ausgeben zu wollen. Letztlich ist es hier natürlich egal, ob Sie die Kundennummer aus der Zahlungs- oder Kundentabelle ausgeben. Die beiden sind ja wertmäßig identisch. So haben wir es in der Verknüpfungsbedingung festgelegt.
+----------+------+-----------+----------+---------+ |payment_id|amount|customer_id|first_name|last_name| +----------+------+-----------+----------+---------+ |17503 |7.99 |341 |Peter |Menard | |17504 |1.99 |341 |Peter |Menard | |17505 |7.99 |341 |Peter |Menard | |17506 |2.99 |341 |Peter |Menard | |17507 |7.99 |341 |Peter |Menard | ... (16049 Datensätze insgesamt)
JOIN – die bessere Tabellenverknüpfung
Ich habe es oben bereits angedeutet. Es ist für die Lesbarkeit und das leichtere Verständnis des Codes einer Abfrage sinnvoll, Datensatzauswahlbedingungen von Tabellenverknüpfungsbedingungen zu trennen. Dazu gibt es das Schlüsselwort JOIN. Und das gibt es in verschiedenen „Geschmacksrichtungen“, die jeweils auf unterschiedliche Arten und Weisen Tabellen miteinander verknüpfen.
INNER JOIN
Der sogenannte INNER JOIN, eine innere Verknüpfung, verlangt, nur die Datensätze einer Tabelle mit der einer anderen zu verknüpfen, wenn die Verknüpfungsbedingung bezüglich beider Tabellen erfüllt ist.
Die am häufigsten genutzte Verknüpfungsbedingung verlangt die Gleichheit eines oder auch mehrerer Attribute, über welche zwei Tabellen miteinander verknüpft werden sollen. Man spricht daher auch von einem Equi-Join. – In Inner Join muss jedoch nicht zwingend ein Equi-Join sein. Die Vergleichsbedingung, welche das Verknüpfungskriterium darstellt, kann auch jede andere Art von Bedingung sein. In den meisten Fällen der Praxis werden Sie aber wohl einen Equi-Join nutzen. Irgendwann werde ich hier, auf dieser Website, auch Nested Sets behandeln. Bei dieser Datenstruktur werden Sie ganz andere Join-Bedingungen als den Equi-Join sehen. – Das aber nur als Hinweis/Ausblick.
Jetzt aber zur Syntax des Inner-Joins:
|
1 2 3 4 5 |
SELECT select_list FROM table1 [INNER] JOIN table2 ON join_condition; |
Das INNER ist der Standard, weshalb die Angabe optional ist. In der Praxis schenkt man sie sich im Allgemeinen. join_condition ist die Verknüpfungsbedingung. Sie kann sich, wenn erforderlich auch aus mehreren Teilbedingungen zusammensetzen, so wie Sie das schon gelernt haben.
Unser bisheriges Statement, Zahlungen und die dazugehörigen Kunden abzufragen, können wir wie folgt umformulieren.
|
1 2 3 4 5 6 7 8 |
SELECT payment_id , amount , c.customer_id , first_name , last_name FROM payment AS p JOIN customer AS c ON p.customer_id = c.customer_id; |
Jetzt ist klar, p.customer_id = c.customer_id verknüpft die beteiligten Tabellen, stellt keine eigentliche Begrenzung der Datensatzauswahl dar. – Ich habe hier gleich die Aliasbezeichner der Tabellen verwendet. Die können Sie in Zusammenhang mit JOIN uneingeschränkt verwenden, um sich die Schreibarbeit zu vereinfachen.
In Verbindung mit einem Vergleich auf Gleichheit bilden wir die Schnittmenge der Daten aus den (zwei) beteiligten Tabellen.
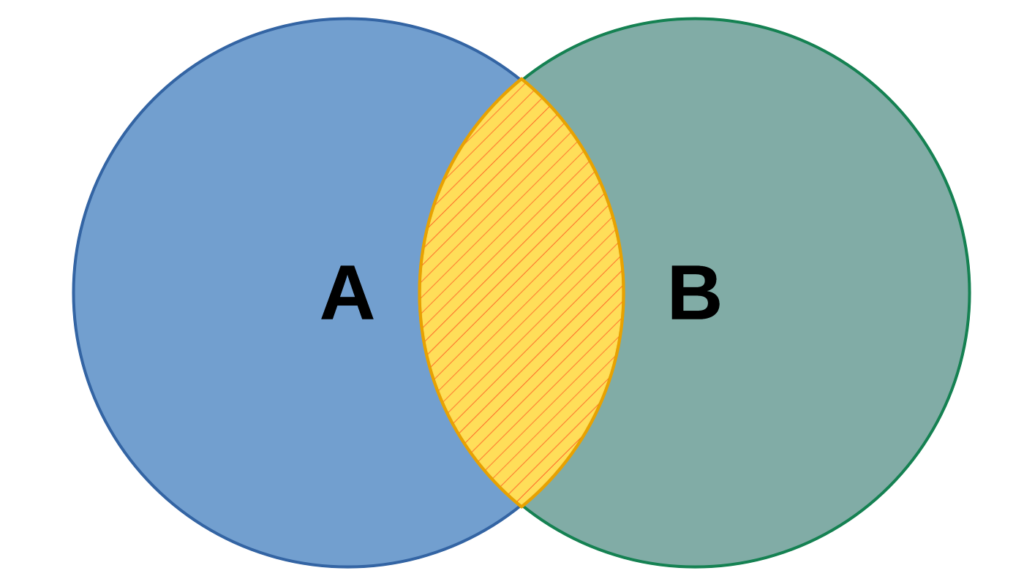
Im vorliegenden Beispiel gibt es keine Zahlungen, zu denen kein Kunde ermittelt werden kann. Ebenso gibt es keine Kunden, die bislang keine Zahlungen geleistet haben. D.h., im konkreten Beispiel der Kunden und Zahlungen, sind alle Datensätze aus beiden Tabellen in der Schnittmenge enthalten. Dabei werden die Datensätze aus der Kundentabelle mehrfach ausgegeben, wenn ein Kunde mehrere Zahlungen geleistet hat. – Wir werden noch Fälle kennenlernen, in denen es nicht für alle Datensätze Entsprechungen in den verknüpften Tabellen gibt.
Wollen wir die ausgewählten Datensatzauswahl einschränken, z.B. auf Zahlungen, die größer als 10.0 Dollar waren, so formulieren wir, wie bereits gehabt, eine entsprechende WHERE-Bedingung.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT payment_id , amount , c.customer_id , first_name , last_name FROM payment AS p -- Tabellenverknüpfungsbedingung JOIN customer AS c ON p.customer_id = c.customer_id -- Datensatzauswahlbedingung WHERE amount > 10.0; |
Sie sehen, auch ohne die eingefügten Kommentare, sind die Bedingungen für die Tabellenverknüpfung und die Datensatzauswahl klar voneinander abgegrenzt und das Statement ist einfach zu lesen und zu verstehen.
+----------+------+-----------+----------+---------+ |payment_id|amount|customer_id|first_name|last_name| +----------+------+-----------+----------+---------+ |18035 |10.99 |477 |Dan |Paine | |18153 |10.99 |511 |Chester |Benner | |18175 |10.99 |516 |Elmer |Noe | |18265 |10.99 |542 |Lonnie |Tirado | |18272 |10.99 |544 |Cody |Nolen | ... (114 Datensätze insgesamt)
Natürlich können wir auch mehr als zwei Tabellen miteinander verknüpfen. Das Prinzip bleibt gleich. Nehmen wir als Beispiel die Tabelle staff hinzu, um zu erfahren, welcher Mitarbeiter die Zahlung gebucht hat.
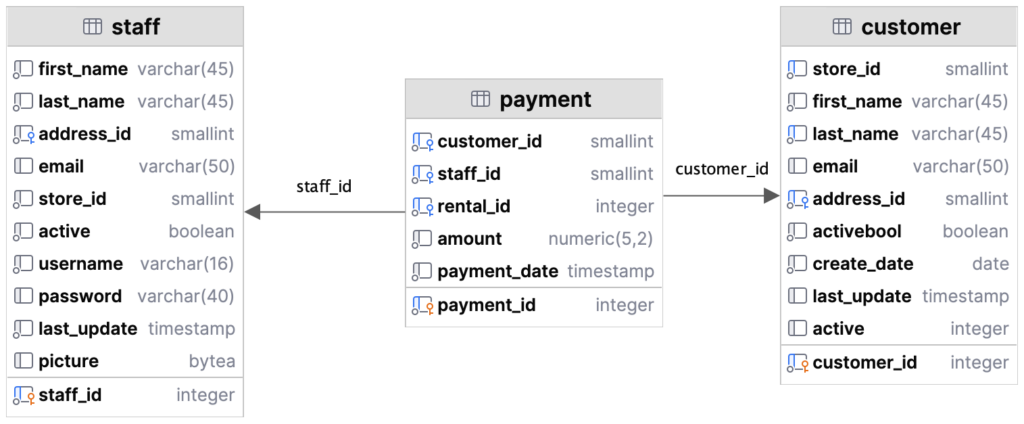
Wie das ER-Diagramm zeigt, sind Zahlungen und Kunden über das Attribut customer_id verknüpft. Das haben wir bereits genutzt. Die Mitarbeiter der Tabelle staff sind über das Attribut staff_id mit den Zahlungen verbandelt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT payment_id , amount , c.customer_id , c.first_name || ' ' || c.last_name AS cust_name , s.first_name || ' ' || s.last_name AS staff_name FROM payment AS p -- Tabellenverknüpfungsbedingung Zahlungen und Kunden JOIN customer AS c ON p.customer_id = c.customer_id -- Tabellenverknüpfungsbedingung Zahlungen und Mitarbeiter JOIN staff AS s ON s.staff_id = p.staff_id -- Datensatzauswahlbedingung WHERE amount > 10.0; |
Weil die Attributnamen first_name und last_name sowohl in der Kunden- als auch der Mitarbeitertabelle verwendet werden, müssen wir den Zugriff auf diese Attribute mit den jeweiligen Tabellennamen qualifizieren. Ich habe hier Aliasbezeichner genutzt.
Die Namen von Kunden und Mitarbeitern habe ich jeweils konkateniert und den resultierenden Spalten passende Namen gegeben. Das sieht hier besser aus, wie ich meine.
Die einschränkende Datensatzauswahlbedingung habe ich beibehalten.
+----------+------+-----------+--------------+------------+ |payment_id|amount|customer_id|cust_name |staff_name | +----------+------+-----------+--------------+------------+ |18035 |10.99 |477 |Dan Paine |Mike Hillyer| |18153 |10.99 |511 |Chester Benner|Jon Stephens| |18175 |10.99 |516 |Elmer Noe |Mike Hillyer| |18265 |10.99 |542 |Lonnie Tirado |Jon Stephens| |18272 |10.99 |544 |Cody Nolen |Jon Stephens| |18290 |10.99 |550 |Guy Brownlee |Mike Hillyer| ... (114 Datensätze insgesamt)
OUTER JOIN
Nicht immer finden sich gemeinsame Werte, die zwei Tabellen miteinander verknüpfen. Zum Beispiel listen wir in der Tabelle film Filmtitel, die uns zwar bekannt sind, für die wir aber keine Datenträger in unserem Inventar, der Tabelle inventory finden. Nun kann es dennoch interessant sein, alle uns bekannten Filme aufzulisten und bei denen, die wir im Inventar haben, deren Inventarnummer zu zeigen. Für die Filmtitel, die nicht im Inventar vorhanden sind, können wir keine Inventarnummer ausgeben. SQL gibt dafür den Wert NULL aus. Dafür ist keine Inventarnummer bekannt.
Der schon bekannte Inner-Join mit einer auf Gleichheit basierenden Verknüpfungsbedingung hilft uns hier nicht weiter. Probieren Sie es aus. – Die erhalten nur Filme in der Ausgabe, die eine Inventarnummer haben. Das liegt an der Konstruktion der Abfrage mit einem Inner-Join.
Ein Outer-JOIN verknüpft zwei Tabellen dergestalt, aus einer Tabelle alle Datensätze zu liefern und aus der anderen die dazu assoziierten Datensätze, je nach Verknüpfungsbedingung. Wir unterscheiden den LEFT OUTER JOIN und den RIGHT OUTER JOIN. Das Wörtchen OUTER ist dabei optional und wird in der Praxis oft weggelassen.
LEFT JOIN
Ein OUTER JOIN funktioniert in dem Sinne, dass die Tabelle, auf die LEFT oder RIGHT verweist, in Gänze in die Auswahl einfließt. Aus der anderen werden nur die dazu passenden Datensätze verknüpft. Bei LEFT werden alle Datensätze der links von der JOIN-Klausel stehenden Tabelle berücksichtigt, bei RIGHT entsprechend umgekehrt.

Bei einem Right-Join würde die Menge B vollständig in der Ergebnismenge enthalten sein und von A nur diejenigen Datensätze, die auch in B sind. Für alle weiteren würden NULLWerte ausgewiesen.
Schauen wir uns das in der Praxis an, dann wird der Sachverhalt unmittelbar klar.
Das Attribut film_id ist das Verknpüfungselement zwischen den beiden Tabellen.
Wir wollen alle Filmtitel ausgeben, die uns bekannt sind. Haben wir einen Titel in unserem Inventar, soll die Inventarnummer dazu ausgegeben werden, andernfalls NULL.
|
1 2 3 4 5 6 7 8 9 |
SELECT f.film_id , title , inventory_id FROM film AS f -- alle Datensätze aus Film (links) LEFT JOIN inventory AS i ON i.film_id = f.film_id ORDER BY title; |
+-------+----------------+------------+ |film_id|title |inventory_id| +-------+----------------+------------+ |1 |Academy Dinosaur|6 | |1 |Academy Dinosaur|1 | |1 |Academy Dinosaur|4 | ... |13 |Ali Forever |69 | |13 |Ali Forever |70 | |14 |Alice Fantasia |null | |15 |Alien Center |74 | |15 |Alien Center |71 | ... (4623 Datensätze insgesamt)
Das sind offensichtlich mehr Datensätze als die Tabelle inventory (4.581 Datensätze) enthält. Im Inventar können nur Filme gespeichert werden, für die es einen Eintrag in der Filmtabelle gibt. Für alle inventarisierten Datenträger gibt es also einen zugeordneten Film. Daneben gibt es aber Filme, für die wir keinen Datenträger im Inventar haben. Auch diese werden von der Abfrage geliefert, woraus die Anzahl der Datensätze resultiert.
Wir können das aber gerne prüfen. Schauen wir uns doch nur die Filme an, die im Inventar fehlen, für die wir keinen Datenträger zum Verleihen besitzen.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT f.film_id , title , inventory_id FROM film AS f -- alle Datensätze aus Film (links) LEFT JOIN inventory AS i ON i.film_id = f.film_id -- wenn Film im Inventar nicht vorhanden, ist die ID NULL WHERE inventory_id IS NULL ORDER BY title; |
Das sind 42 Filme:
+-------+----------------------+------------+ |film_id|title |inventory_id| +-------+----------------------+------------+ |14 |Alice Fantasia |null | |33 |Apollo Teen |null | |36 |Argonauts Town |null | |38 |Ark Ridgemont |null | |41 |Arsenic Independence |null | |87 |Boondock Ballroom |null | |108 |Butch Panther |null | |128 |Catch Amistad |null | |144 |Chinatown Gladiator |null | |148 |Chocolate Duck |null | |171 |Commandments Express |null | |192 |Crossing Divorce |null | |195 |Crowds Telemark |null | |198 |Crystal Breaking |null | |217 |Dazed Punk |null | |221 |Deliverance Mulholland|null | |318 |Firehouse Vietnam |null | |325 |Floats Garden |null | |332 |Frankenstein Stranger |null | |359 |Gladiator Westward |null | |386 |Gump Date |null | |404 |Hate Handicap |null | |419 |Hocus Frida |null | |495 |Kentuckian Giant |null | |497 |Kill Brotherhood |null | |607 |Muppet Mile |null | |642 |Order Betrayed |null | |669 |Pearl Destiny |null | |671 |Perdition Fargo |null | |701 |Psycho Shrunk |null | |712 |Raiders Antitrust |null | |713 |Rainbow Shock |null | |742 |Roof Champion |null | |801 |Sister Freddy |null | |802 |Sky Miracle |null | |860 |Suicides Silence |null | |874 |Tadpole Park |null | |909 |Treasure Command |null | |943 |Villain Desperate |null | |950 |Volume House |null | |954 |Wake Jaws |null | |955 |Walls Artist |null | +-------+----------------------+------------+
4.623 minus 42 sind 4.581 – passt!
RIGHT JOIN
Der RIGHT JOIN ist prinzipiell gleich seinem LEFT-Pendant. Es werden lediglich die Tabellen in Bezug auf deren Position zu JOIN vertauscht. Und natürlich schreiben wir dann auch entsprechend RIGHT statt LEFT.
|
1 2 3 4 5 6 7 8 9 |
SELECT f.film_id , title , inventory_id FROM inventory AS i -- alle Datensätze aus Film (rechts) RIGHT JOIN film AS f ON i.film_id = f.film_id ORDER BY title; |
Anmerkung: Einige Datenbankmanagementsysteme, so auch PostgreSQL, unterstützen auch einen FULL OUTER JOIN. Das ist die Vereinigungsmenge der Resultate eines LEFT und eines RIGHT OUTER JOIN. Wir betrachten das separat, wenn wir uns mit Vereinigungsmengen etc. befassen. PostgreSQL biete auch noch weitere Spielarten von Joins. Das sind aber, ebenso wie der Outer-Join, alles Spielarten, die möglicherweise eine Vereinfachung darstellen, jedoch nichts bieten, was nicht mit den drei besprochenen Verknüpfungsarten zuzüglich weiterer Operationen, wie z.B. der noch zu besprechenden Vereinigung o.ä., zu bewältigen wäre.
Self-Join
Der Self-Join ist kein neuer Sprachausdruck. Sie brauchen keine neue Syntax zu lernen. Ein Self-Join ist eine Verknüpfung mit sich selbst.
Wir müssen zur Lösung der Aufgabe die Spieldauern von je zwei Filmen vergleichen. D.h., wir müssen die Filmtabelle zweifach in unsere Abfrage integrieren und über gleiche Längen miteinander verknüpfen. Weiterhin benötigen wir eine Regel, die einen Film nicht mit sich selbst verknüpft. Diese Regel soll auch dafür sorgen keine doppelten Paare im Sinne (Film1, Filme2) und (Film2, Film1) zu generieren. Die Reihenfolge der Nennung eines Films soll also keine Rolle spielen. Wenn wir unseren Kunden im Rahmen einer Werbeaktion je zwei Filme gleicher Länge anbieten wollen (seltsame Aktion), ist es für die Kunden irrelevant in welcher Reihenfolge unsere Datenbank die Paare jeweils anordnet. Wir überlegen daher, als zweite Verknüpfungsbedingung zu verlangen, das die ID des erstgenannten Films kleiner als die des zweiten Films sein soll. Das könnten wir ebenso umgekehrt formulieren. Am Ende käme das gleiche heraus, nur wären die Paare eben in umgekehrter Ordnung.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT f1.title , f2.title , f1.length -- Filmtabelle 1 FROM film AS f1 -- Filmtabelle 2 (Self-Join) JOIN film AS f2 -- gleiche Filmlängen ON f1.length = f2.length -- aber unterschiedliche Paarungen AND f1.film_id < f2.film_id ORDER BY f1.length , f1.title , f2.title; |
Wir können eine ganze Menge möglicher Paarungen bilden. Beachten Sie die interessante Konstruktion der Verknüpfungsbedingung.
+------------+-------------------+------+ |title |title |length| +------------+-------------------+------+ |Alien Center|Iron Moon |46 | |Alien Center|Kwai Homeward |46 | |Alien Center|Labyrinth League |46 | |Alien Center|Ridgemont Submarine|46 | |Iron Moon |Kwai Homeward |46 | |Iron Moon |Labyrinth League |46 | ... (3486 Datensätze insgesamt)
Als Beispiel wolle wir alle Paare von Filmen ermitteln, die eine gleich lange Spieldauer haben.