Bäume und Hierachien
In der Informatik bezeichnet der Begriff „Baum“ eine Datenstruktur und abstrakten Datentypen, mit dem sich hierarchische Strukturen abbilden lassen. Damit stellt der Baum eine spezielle Struktur derjenigen Strukturen dar, die Gegenstand der so genannten Graphentheorie sind. Wie alle Strukturen, die in der Graphentheorie behandelt werden, also beispielsweise den schon behandelten Beispielgraphen aus Kapitel „Allgemeiner Graph als Adjazenzliste“, besteht ein Baum aus Knoten und Kanten.
Eine Hierarchie ist wiederum ein spezieller Baum, der durch Über-/Unterordnungsverhältnisse gekennzeichnet ist. Im Falle einer Mitarbeiterhierarchie, wie wir sie in Unternehmen vorfinden, kann man auch sagen, dass Macht von oben nach unten vererbt wird. Der Chef oder die Chefin vererben einen Teil ihrer Macht an die jeweils untergeben Mitarbeiterinnen und Mitarbeiter. Die geben ihrerseits Teile an die Ihnen Untergebenen weiter. Fällt eine Person in der Hierarchie aus, zerbricht diese nicht. Diejenigen, deren Vorgesetzte(r) ausfällt, unterstehen dann dem/der Vorgesetzten der ausgefallenen Person. Ein einfacher Baum zerbricht dagegen in zwei Bäume, die dann einen sogenannten Wald bilden.
Ein Baum bezeichnet also die Datenstruktur als solches. Eine Hierarchie ist ein Baum, jedoch angereichert um eine gewisse Semantik, durch welche mögliche Operationen eingeschränkt werden. Weil gerade diese Einschränkungen eine Herausforderung darstellen können, wollen wir uns im Folgenden als Beispiel eine Hierarchie anschauen und implementieren.
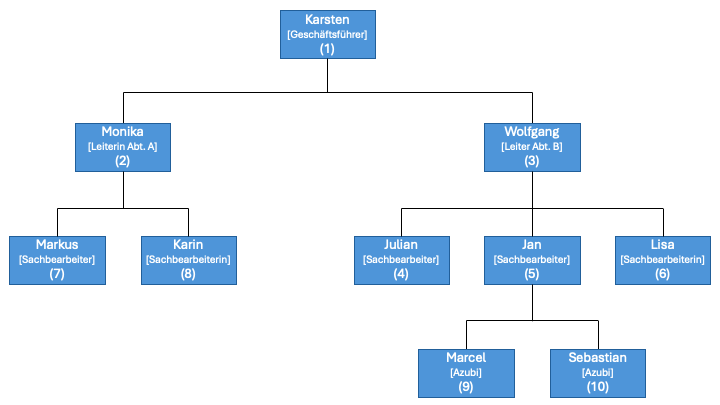
In Klammern sind die Mitarbeiternummern der Personen des Unternehmens notiert. Ihre jeweilige Funktion/Rolle ist klein in eckigen Klammern angegeben.
Ein Baum, also ebenso eine Hierarchie, ist eine rekursive Datenstruktur. Ein Baum ist entweder leer oder besteht aus einem Knoten. Diesem Knoten können kein, ein Element oder gar mehrere Elemente zugeordnet sein, für die selbiges gilt.
Wir können, Sie ahnen es, auch eine solche Struktur problemlos mithilfe einer Adjazenz-liste abbilden. Ich habe hier jedoch absichtlich eine Hierarchie als Beispiel gewählt, um Ihnen zu zeigen, wie Sie mit Beschränkungen umgehen, diese implementieren, die Ihnen die Semantik der Struktur auferlegt.
Schauen wir uns an, welche Regeln wir formulieren können/müssen, um zu gewährleisten, dass die eingegebenen Daten immer eine Hierarchie bilden. Hierzu möchte ich eine Überlegung vorwegschicken. Wir wollen für jeden Mitarbeiter erfassen, wer dessen Vorgesetzter ist. Ein solches Paar bildet eine Kante. Der Chef, der Geschäftsführer, hat keinen Vorgesetzten. Er bildet die Wurzel des Baumes. Die soll dadurch gekennzeichnet sein, als Vorgesetztenangabe den Wert NULL zu haben. Man kann das auch anders modellieren. Diese Entscheidung ist jedoch günstig für alle weiteren Regeln und Entscheidungen, die wir zu treffen haben.
- Ein nicht-leerer Baum hat genau eine Wurzel.
- Eine Hierarchie zerbricht nicht.
- Ein Baum/eine Hierarchie ist zyklenfrei.
Um die Integrität der Daten zu gewährleisten, müssen weitere Sachverhalte beachtet werden:
- Es dürfen nur Personen in der Hierarchie aufgenommen werden, ob als vorgesetzte oder untergebene Person, die auch Mitarbeiter sind.
- Ein untergeordneter Mitarbeiter darf nur auf eine vorgesetzte Person verweisen, wenn diese in der Hierarchie bereits erfasst ist.
- Jeder Mitarbeiter hat genau einen Vorgesetzten. Ausnahme: Der Chef hat keinen Vorgesetzten.
- Ein Mitarbeiter ist sich nicht selbst vorgesetzt.
Die obigen Regeln sind nicht frei von Redundanzen, helfen uns aber, wenn wir sie so ausführlich formulieren, die erforderlichen Regeln für unsere Beispielhierarchie zu implementieren.
Implementierung
Strukturelle Implementierung der Beispielhierarchie
Nicht alle Regeln lassen sich in der Datenstruktur selbst implementieren, weshalb wir die Implementierung aufteilen.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE mitarbeiter ( ma_id BIGINT NOT NULL PRIMARY KEY, vorname VARCHAR(30) NOT NULL DEFAULT '{{ vakant }}' ); INSERT INTO mitarbeiter (ma_id, vorname) VALUES ( 1, 'Karsten'), ( 2, 'Monika'), ( 3, 'Wolfgang'), ( 4, 'Julian'), ( 5, 'Jan'), ( 6, 'Lisa'), ( 7, 'Markus'), ( 8, 'Karin'), ( 9, 'Marcel'), (10, 'Sebastian'); |
In der Hierarchie bilden wir nun, soweit möglich, einige der oben genannten Regeln als Zeilen- oder Tabellenregeln ab.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE hierarchie ( u_id BIGINT NOT NULL PRIMARY KEY -- untergebene Person REFERENCES mitarbeiter (ma_id) ON DELETE RESTRICT -- CASCADE explizit unterbunden ON UPDATE CASCADE, v_id BIGINT NULL -- vorgesetzte Person CHECK ( v_id != u_id ) REFERENCES hierarchie (u_id) ON DELETE RESTRICT -- CASCADE explizit unterbunden ON UPDATE CASCADE, rolle VARCHAR(30) NOT NULL DEFAULT 'Sachbearbeiter', wurzel CHAR(1) GENERATED ALWAYS AS (CASE WHEN v_id IS NULL THEN '-' END) STORED UNIQUE ); |
Was haben wir bereits wie erreicht?
- Durch einen Fremdschlüsselverweis stellen wir sicher, nur Mitarbeiter (
u_id) in der Hierarchie erfassen zu können, die auch in der Mitarbeitertabelle verzeichnet sind. - Durch einen selbstverweisenden Fremdschlüsselverweis stellen wir sicher, nur auf Vorgesetzte (
v_id) zu verweisen, die a) bereits in der Hierarchie als Mitarbeiter erfasst sind, wodurch wir b) ebenso sicherstellen, dass es sich um Personen aus der Mitarbeitertabelle handelt. Andernfalls könnten wir sie nicht als Mitarbeiter (u_id) erfasst haben. - Der erste zu erfassende Datensatz muss den Wurzelknoten repräsentieren.
v_idist optional einzugeben, widerspricht also nicht den definierten referentiellen Integritätsregeln. Die Wurzel ist der einzige Datensatz, der keinen Vorgesetzten benennen muss. Alle weiteren Datensätze müssen einen solchen konkret benennen. Wegen desUNIQUE-Indexes für das virtuelle Feldwurzelkann es nur eine einzige Wurzel geben. - Weil
u_idder Primärschlüssel ist, kann jeder Mitarbeiter nur einfach in der Hierarchie als untergebener Mitarbeiter aufgenommen werden. Gleichzeitig kann er auch nur maximal einen Vorgesetzten haben. - Bei der Dateneingabe ist es nicht möglich einen Zyklus zu etablieren, weil der Verweis auf den Vorgesetzten nur auf eine Person erfolgen kann, die bereits erfasst ist. Ein untergebener Mitarbeiter kann also nicht erfasst sein, sodass ein solcher Zyklus ausgeschlossen ist.
- Selbstverweise, die einen Mitarbeiter zu seinem eigenen Vorgesetzten machen, sind ausgeschlossen.
Obgleich PostgreSQL kaskadierendes Löschen auch bei sich selbst referenzierenden Tabellen unterstützt, habe ich es hier explizit untersagt, um das versehentliche Löschen ganzer Teilbäume zu unterbinden. In dieser Form können lediglich Mitarbeiter aus der Hierarchie gelöscht werden, die nicht auch Vorgesetzte sind. – Daraus folgt eine interessante Art und Weise des Löschens von Teilbäumen. Dabei müssen wir nämlich die Reihenfolge der zu löschenden Mitarbeiter (Knoten) beachten.
Geben wir unsere Beispieldatensätze ein:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT INTO hierarchie (u_id, v_id, rolle) VALUES ( 1, NULL, 'Geschäftsführer') , ( 2, 1, 'Leiterin Abt. A') , ( 3, 1, 'Leiter Abt. B') , ( 7, 2, 'Sachbearbeiter') , ( 8, 2, 'Sachbearbeiterin') , ( 4, 3, 'Sachbearbeiter') , ( 5, 3, 'Sachbearbeiter') , ( 6, 3, 'Sachbearbeiterin') , ( 9, 5, 'Azubi') , (10, 5, 'Azubi'); |
Was haben wir noch nicht erreicht?
- Aktuell können wir via UPDATE einen Mitarbeiter zu einem Untergebenen eines untergebenen Mitarbeiters machen. Das etabliert a) einen Zyklus und b) zerbricht die Hierarchie.
123456UPDATE hierarchieSET v_id = 9WHERE u_id = 3;SELECT *FROM hierarchie;
+----+----+----------------+------+ |u_id|v_id|rolle |wurzel| +----+----+----------------+------+ |1 |null|Geschäftsführer |- | |2 |1 |Leiterin Abt. A |null | |7 |2 |Sachbearbeiter |null | |8 |2 |Sachbearbeiterin|null | |4 |3 |Sachbearbeiter |null | |5 |3 |Sachbearbeiter |null | -- Zyklus: 3-5-9-3 |6 |3 |Sachbearbeiterin|null | -- Hierarchie dadurch zerbrochen |9 |5 |Azubi |null | |10 |5 |Azubi |null | |3 |9 |Leiter Abt. B |null | +----+----+----------------+------+
- Wir können nur Mitarbeiter löschen, die nicht als Vorgesetzte registriert sind. Das ist gegebenenfalls mühsam. Auch wenn es sinnvoll ist, das Löschen ganzer Teilbäume durch ein versehentliches
DELETEzu unterbinden, sollte dennoch eine Möglichkeit geschaffen werden, diese Aufgabe einfach und effizient zu bewältigen.
Gedanken zur Prozeduralen Implementierung der Beispielhierarchie
Um die genannten Mängel in unserer Hierarchie zu beheben, benötigen wir prozedurale Programmierung. Das mangelhafte Verhalten, bei einem UPDATE die Hierarchie zu zerbrechen und einen Zyklus zu etablieren, können wir mit einem entsprechenden Trigger abfangen. Für das Löschen ganzer Teilbäume schreiben wir uns eine Prozedur.
Bevor wir uns an die Arbeit machen können, müssen wir jedoch noch einige der wichtigsten Abfragen kennenlernen, die auf Bäumen/Hierarchien angewendet werden.
Wichtige Abfragen auf Bäumen/Hierarchien
Finden der Wurzel
Das Finden der Wurzel ist trivial. Sie ist gegenüber den anderen Knoten dadurch ausgezeichnet, keinen Verweis auf einen Vorgesetzten zu haben. Allgemein sprechen wir von Kind- und Elternknoten. Die Wurzel hat als einziger Knoten keinen Elternknoten. Wir haben in unserem Beispiel NULL gewählt. Bei jeder anderen Modellierung, wäre die Wurzel jedoch ebenso leicht zu identifizieren.
|
1 2 3 4 5 6 7 8 |
CREATE VIEW wurzel AS SELECT u_id , v_id , rolle FROM hierarchie WHERE v_id IS NULL; |
Blätter finden
Die Blätter eines Baumes sind dadurch gekennzeichnet, keine Kindknoten (Untergebene) zu besitzen. Anders und in Bezug auf das konkrete Beispiel formuliert, sind die Blätter jene Knoten, deren Mitarbeiter keine Untergebenen haben. Diese Mitarbeiter werden also nicht von anderen Knoten als Vorgesetzte referenziert. Daraus ergibt sich direkt die entsprechende Abfrage, die mit Hilfe einer korrelierten Unterabfrage formuliert ist.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE VIEW blaetter AS SELECT u_id , rolle FROM hierarchie h1 WHERE NOT exists ( SELECT * FROM hierarchie h2 WHERE h1.u_id = h2.v_id ); |
Levels/Ebenen
Die Länge eines Pfades zwischen Knoten eines Subordinationsverhältnisses bezeichnen wir als Pfadlänge. Die Maßeinheit ist die Anzahl der Level (Ebenen), die wir vom Start- zum Endknoten gehen müssen. Der Wurzelknoten hat per Konvention das Level 0.
Wir traversieren den kompletten Baum der Hierarchie, beginnend beim Wurzelknoten. Dazu nutzen wir einen rekursiven CTE, in dessen Ankerabfrage die Wurzel adressieren. Genauer gesagt suchen wir die Kante, die die Wurzel kennzeichnet. Das ist die eine Kante, deren Vorgesetztenverweis NULL ist. Innerhalb der Rekursionsabfrage suchen wir dann jeweils die Kindknoten bzw. die Anschlusskanten. Die sind dadurch gekennzeichnet, als Elternverweis (v_id) auf eine bereits gefundene u_id zu verweisen. – Das Ganze ist vollkommen analog zum Traversieren eines allgemeinen Graphen, mit dem Unterschied, eine einzige Kante als Startkante in der Ankerabfrage zu nutzen.
Für die Fragestellung wären u_id und ebene ausreichend. Ich bevorzuge es jedoch, auch die weiteren Informationen, wie den Vorgesetztenverweis und die Rolle mit auszugeben.
Da wir die Informationen direkt und ohne Tabellenverknüpfung erlangen können, kostet sie uns nichts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE VIEW ebenen(u_id, v_id, rolle, ebene) AS WITH RECURSIVE teilbaum (u_id, v_id, rolle, ebene) AS ( SELECT u_id , v_id , rolle , 0 FROM hierarchie WHERE hierarchie.v_id IS NULL-- Wurzel -> Traversierung des gesamten Baums UNION ALL SELECT h.u_id , h.v_id , h.rolle , t.ebene + 1 FROM hierarchie h JOIN teilbaum t ON h.v_id = t.u_id ) SELECT u_id , v_id , rolle , ebene FROM teilbaum; |
+----+----+----------------+-----+ |u_id|v_id|rolle |ebene| +----+----+----------------+-----+ |1 |null|Geschäftsführer |0 | |2 |1 |Leiterin Abt. A |1 | |3 |1 |Leiter Abt. B |1 | |7 |2 |Sachbearbeiter |2 | |8 |2 |Sachbearbeiterin|2 | |4 |3 |Sachbearbeiter |2 | |5 |3 |Sachbearbeiter |2 | |6 |3 |Sachbearbeiterin|2 | |9 |5 |Azubi |3 | |10 |5 |Azubi |3 | +----+----+----------------+-----+
Die Ausgabe ist wie folgt zu verstehen:
- Der Knoten 1 hat keinen Vorgesetzten (
NULL). Ihm ist die Rolle „Geschäftsführer“ zugewiesen und befindet sich in der Hierarchie auf Ebene 0. - Konten 2 hat Knoten 1 als vorgesetzte Person. Die Rolle lautet „Leiterin Abt. A„. Der Knoten befindet sich auf Ebene 1.
- …
Teilbaum ermitteln
Das Ermitteln eines Teilbaums entspricht prinzipiell der Traverse durch den ganzen Baum. Statt jedoch bei der Wurzel zu starten, beginnt die Traverse bei einem anderen Knoten.
Weil Sichten nicht parametrisierbar sind, bietet es sich an, für derartige Zwecke Funktionen zu verwenden.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE FUNCTION teilbaum(_u_id BIGINT) RETURNS TABLE ( uid BIGINT, vid BIGINT, funktion VARCHAR(30), ebene INTEGER ) AS $$ BEGIN RETURN QUERY WITH RECURSIVE teilbaum (u_id, v_id, rolle, level) AS ( SELECT u_id , v_id , rolle , 0 as level FROM hierarchie WHERE u_id = _u_id -- Traversierung ab '_u_id' (inkl.) UNION ALL SELECT h.u_id , h.v_id , h.rolle , level + 1 FROM hierarchie h JOIN teilbaum t ON h.v_id = t.u_id ) SELECT u_id , v_id , rolle , level FROM teilbaum; END; $$ LANGUAGE plpgsql; |
Finden eine bestimmten Pfades
Wenn wir den Baum aufspannen, so wie wir es bereits getan haben, ist es leicht, die Pfade zwischen den Knoten zu protokollieren. Suchen wir einen bestimmten Pfad, die Verbindung zwischen zwei konkreten Knoten, ist es jedoch ineffizient den gesamten Baum aufspannen zu wollen. Das gilt selbst dann, wenn wir die Rekursion abbrechen, wenn der gesuchte Unterknoten gefunden wurde.
Machen wir uns klar, dass es in einem Baum, so es einen Pfad zwischen zwei Knoten gibt, dieser Pfad eindeutig ist. Dann können wir die Suche von unten starten. Wir beginnen beim untergeordneten Knoten und wandern den Baum aufwärts. Dabei verfolgen wir lediglich einen einzigen Pfad. Der endet spätestens bei der Wurzel.
Wird der untergeordnete Knoten nicht gefunden, erübrigt sich eine weitere Suche bereits. Wird der Unterknoten gefunden, wird nur der Pfad verfolgt, der von diesem Unterknoten in Richtung Wurzel führt. Wird auf dem Weg dorthin der Oberknoten gefunden, gibt es einen Pfad, andernfalls nicht.
Diese Art der Suche ist sehr viel effizienter als das Aufspannen des Baumes. Wir können so suchen, weil die Struktur eines Baumes für jeden Pfad im Baum gewährleistet, einzigartig zu sein. Es gibt keine verschiedenen Verbindungen zwischen zwei Knoten.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE FUNCTION suche_pfad(_u_id BIGINT, _v_id BIGINT) RETURNS TABLE ( uid BIGINT, vid BIGINT, laenge INTEGER, pfad TEXT ) AS $$ BEGIN RETURN QUERY WITH RECURSIVE pfad (maid, managerid, anzahl, knoten) AS ( SELECT u_id , v_id , 1 AS anzahl , u_id || ',' || v_id AS knoten FROM hierarchie WHERE u_id = _u_id -- von unten nach oben!!! UNION ALL SELECT pfad.maid , h.v_id , pfad.anzahl + 1 , h.v_id || ',' || pfad.knoten FROM hierarchie h JOIN pfad ON h.u_id = pfad.managerid AND h.u_id != _v_id ) SELECT * FROM pfad WHERE pfad.managerid = _v_id AND pfad.maid = _u_id; END; $$ LANGUAGE plpgsql; |
|
1 2 |
SELECT * FROM suche_pfad(9, 3); |
+---+---+------+-----+ |uid|vid|laenge|pfad | +---+---+------+-----+ |9 |3 |2 |3,9,5| +---+---+------+-----+
Die Ausgabe eines Pfades habe ich hier von oben nach unten gestaltet, dem Subordina-tionsverhältnis entsprechend.
Prozedurale Programmierung der Beispielhierarchie
UPDATE-Trigger
Die oben erörterten Abfragen geben uns das Rüstzeug an die Hand, die Struktur unseres Baumes, der Unternehmenshierarchie, abzusichern bzw. das Löschen von Teilbäumen auch ohne kaskadierendes DELETE komfortabel zu lösen.
Wir hatten uns angesehen, eine UPDATE-Operation durchführen zu können, bei welcher ein vorgesetzter Mitarbeiter zu einem Untergebenen seiner selbst werden konnte. Damit waren zwei Unannehmlichkeiten einhergegangen, die es zu vermeiden gilt. Wir hatten damit einen Zyklus implementiert und die Struktur ist in zwei Teilbäume zerbrochen.
Da wir jetzt aber herausgearbeitet haben, wie wir einen Pfad zwischen zwei Knoten suchen und finden, können wir solch Ungemach leicht unterbinden. Wir haben lediglich zu prüfen, ob eine potentielle UDATE-Operation eine vorgesetzte Person sich selbst zum Untergebenen macht. Hierzu spendieren wir uns eine Funktion vor_update_trigger(), die unsere Funktion suche_pfad() aufruft. Wird ein solcher Pfad gefunden, wird die Operation abgebrochen. Andernfalls ist die UPDATE-Operation erlaubt und wird durchgeführt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE OR REPLACE FUNCTION vor_update_hierarchie() RETURNS TRIGGER AS $$ DECLARE _zaehler INTEGER := 0; BEGIN -- Zykluserkennung -- -- Prüfe, ob der neue Vorgesetzte nicht Untergebener ist. -- Wenn ja -> FEHLER SELECT count(*) INTO _zaehler FROM ( SELECT * FROM suche_pfad(new.v_id, old.u_id) ) hlp; IF (_zaehler > 0) THEN RAISE EXCEPTION 'Zyklus registriert.'; END IF; RETURN new; END; $$ LANGUAGE plpgsql; CREATE TRIGGER vor_update_hierarchie BEFORE UPDATE ON hierarchie FOR EACH ROW EXECUTE FUNCTION vor_update_hierarchie(); |
Innerhalb der Trigger-Funktion müssen wir lediglich auf den korrekten Aufruf von suche_pfad() achten.
|
1 2 3 |
UPDATE hierarchie SET v_id = 9 WHERE u_id = 3; |
Ist der angegebene Vorgesetzte (new.v_id) bereits Untergebener des zu modifizierenden Mitarbeiters (old.u_id), würde ein Zyklus etabliert.
Datenmanipulationen auf einem Baum
Dank der getroffenen Vorbereitungen sind die Operationen, die Daten auf einem Baum, der als Adjazenzliste implementiert ist, weitestgehend trivial. Lediglich dem Vertauschen von Knoten innerhalb des Baumes werden wir uns etwas intensiver widmen müssen. Alle anderen Operationen, die wir zuerst behandeln werden, sind einfach zu implementieren. Die umgesetzten Regeln, struktureller und prozeduraler Natur, stellen die Integrität unseres Baumes, der Unternehmenshierarchie, sicher.
Einfügen eines Knotens
Das Einfügen eines Knotens ist trivial. Unter Berücksichtigung der Integritätsbedingungen ist ein Knoten (Mitarbeiter) anzulegen, der dann mit Hilfe eines einfachen INSERT-Statements in die Kantentabelle (Organisationsstruktur) eingefügt werden kann.
|
1 2 3 4 5 |
INSERT INTO mitarbeiter (ma_id, vorname) VALUES (11, 'Donald'); INSERT INTO hierarchie(u_id, v_id, rolle) VALUES (11, 1, 'Assistent'); |
Weil wir ein kaskadierendes Löschen bei der Definition der Hierarchie ausgeschlossen haben, sorgen die Fremdschlüsselbeziehungen dafür, lediglich Blätter im Baum löschen zu können. Wollen wir also einen ganzen Teilbaum löschen, müssen wir zwingend mit den Blättern beginnen und uns ebenenweise nach oben arbeiten. Die Werkzeuge dazu haben wir uns jedoch bereits geschaffen. Die Funktion teilbaum() liefert die benötigten Informationen, um mit dem PostgreSQL-Feature DELETE … USING ein solches Löschen vornehmen zu können.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE PROCEDURE loesche_teilbaum(_u_id BIGINT) AS $$ BEGIN WITH loeschliste AS ( -- Löschreihenfolge festlegen SELECT uid FROM teilbaum(_u_id) ORDER BY ebene DESC ) DELETE FROM hierarchie USING loeschliste -- Reihenfolge beim Löschen beachten WHERE hierarchie.u_id = loeschliste.uid; END; $$ LANGUAGE plpgsql; |
loeschliste ist eine nach Ebenen absteigend sortierte Liste der Knoten des Teilbaumes, der durch teilbaum() aufgespannt wird. Die USING-Klausel veranlasst DELETE dazu, sich beim Löschen an die Reihenfolge der angegebenen Knoten zu halten. Auf diese Weise wird der Baum von unten nach oben, so wie es gestattet ist, gelöscht. Wird lediglich ein Blattknoten angegeben, leistet die Funktion freilich ebenso ihren Dienst.
Verschieben eines Knotens/Teilbaums
Das Verschieben entspricht einer UPDATE-Operation. Wir haben dafür einen Trigger implementiert.
Vertauschen zweier Knoten
Wie in der Programmierung üblich benötigen wir zum Vertauschen zweier Werte einen Zwischenspeicher, einen Dummy. Den erzeugen wir uns als Zufallswert. Das gewährleistet auch im Mehrbenutzerbetrieb unterschiedliche Werte für den Dummy und vermeidet Kollisionen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE PROCEDURE tausche_knoten(_u_id1 BIGINT, _u_id2 BIGINT) AS $$ DECLARE _dummy BIGINT := ('x' || replace(gen_random_uuid()::TEXT, '-', ''))::BIT(64)::BIGINT; BEGIN -- Zum Vertauschen zweier Knoten wird ein Dummy-Mitarbeiter benötigt. -- Das ist analog zum Tauschen der Inhalte zweier Variablen. IF _u_id1 <> _u_id2 THEN -- es gibt nur etwas zu tun, wenn _u_id1 und -- _u_id2 verschieden sind -- notwendigen Dummy anlegen INSERT INTO mitarbeiter(ma_id, vorname) VALUES (_dummy, '{{ DUMMY }}'); -- tauschen UPDATE hierarchie SET u_id = _dummy WHERE u_id = _u_id1; UPDATE hierarchie SET u_id = _u_id1 WHERE u_id = _u_id2; UPDATE hierarchie SET u_id = _u_id2 WHERE u_id = _dummy; -- am Ende: Dummy löschen DELETE FROM mitarbeiter WHERE ma_id = _dummy; END IF; EXCEPTION -- wenn irgendein Fehler auftritt, Ausnahme werfen WHEN OTHERS THEN RAISE EXCEPTION 'Vertauschen fehlgeschlagen!'; END; $$ LANGUAGE plpgsql; |