Datenbanksysteme
Datenbank, Dateisystem und andere Begriffe werden heutzutage in vielerlei Zusammenhängen verwendet. Im der Regel denken wir sofort an relationale Datenbanken. Der Begriff „Datenbank“ allein ist jedoch problematisch. Man stößt damit fast unweigerlich auf Probleme. Das liegt jedoch nicht an deren mangelnder Definition, vielmehr werden der Begriff im Alltag oftmals schlicht falsch verwendet. So sprechen einige Personen von einer Datenbank, die sie angelegt hätten, wenn Sie Informationen mittels eines Tabellenkalkulationsprogramms strukturiert erfasst und in einer oder auch mehreren entsprechenden Dateien gespeichert haben.
Der Begriff Datei ist ein Kunstwort, bestehend aus den Worten Daten und Kartei. Laut Duden ist eine Datei ein „nach zweckmäßigen Kriterien geordneter, zur Aufbewahrung geeigneter Bestand an sachlich zusammengehörenden Belegen oder anderen Dokumenten, besonders in der Datenverarbeitung“ (vgl. https://www.duden.de/rechtschreibung/Datei).
Der Begriff der Datenbank tauchte erstmalig etwa um das Jahr 1960 auf, wurde jedoch nicht konkret definiert (vgl. Stahlknecht, Einführung in die Wirtschaftsinformatik, 7. Auflage, 1995, Seite 216). Im Laufe der Zeit wurde der Begriff konkretisiert. Wir verstehen darunter das integrierte Ganze einer Datensammlung, aufgezeichnet in einem nach verschiebenden Kriterien direkt zugänglichen Speicher, der für Informationsspeicherung und -beschaffung in großem Umfang bestimmt und durch ein eigenes Programmsystem verwaltet wird (vgl. https://de.wikipedia.org/wiki/Datenbank).
Ein DBMS (Database Management System) ist demnach ein Programmsystem zur Verwaltung einer zusammenhängenden Menge von Daten. Die wesentliche Aufgabe einer Datenbank ist es, große Datenmengen effizient, widerspruchsfrei und dauerhaft zu speichern sowie benötigte Teilmengen in unterschiedlichen, bedarfsgerechten Darstellungsformen für Benutzer und Anwendungsprogramme bereitzustellen (vgl. a.a.O.).
Sie selbst kennen es vielleicht nicht mehr, möglicherweise verwenden Ihre Eltern oder Großeltern es aber noch: ein Adressbuch. Das ist ein kleines gebundenes Buch. Darin gibt es vorgedruckte Seiten, auf denen Sie handschriftlich Namen, Adressen und Telefonnummern notieren können. Die Seiten sind alphabetisch sortiert. Die Anfangsbuchstaben der Namen, die auf einer Seite notiert werden sollen, sind im Seitenkopf oder in Form von Registern auf die Seiten gedruckt.
Ein typisches Problem dieser Bücher besteht darin, dass bei den Buchstaben „X“, „Y“, „Z“ zumeist gähnende Leere herrscht, die Seiten „S“ oder „M“ aber schnell gefüllt sind. Zudem sind die Namen innerhalb eines Registers selten korrekt sortiert erfasst. Die Einträge werden/wurden sequentiell notiert und Sie können sie, wenn Sie sie einmal niedergeschrieben haben, nicht umordnen.
Haben Sie die Adressen nach Nachnamen geordnet notiert, haben Sie ein Problem, wenn Sie sich lediglich an den Vornamen einer Person erinnern, die Sie anrufen möchten. Um die gesuchte Nummer zu finden, müssen Sie Ihr Adressbuch sequentiell durchsuchen, in der Hoffnung, der Nachname möge mit einem Buchstaben nahe dem Anfang des Alphabets beginnen.
Das Adressbuch kann außerdem nur von einer Person zu einer Zeit genutzt werden. Sie können darin keine Adresse nachschlagen, wenn Ihr Bruder oder eine andere Person das Buch bei sich führt und aktuell abwesend ist. Ebenso wenig können Sie eine Adresse nachschlagen oder notieren, wenn eine andere Person das Adressbuch in Gebrauch hat.
Redundanz
Um sowohl nach Nachnamen wie auch Vornamen suchen zu können, könnten Sie auf die Idee kommen, zwei Adressbücher zu führen. In einem ordnen Sie die Einträge nach Nachnamen, im anderen nach Vornamen. Der Datenbestand ist dann jedoch redundant. Jede Änderung, Löschung oder Ergänzung müssen Sie doppelt durchführen. Das kostet Platz und Zeit. Außerdem haben Sie sich ein weiteres Problem eingehandelt.
Inkonsitenz
Verpassen Sie es, eine Modifikation des einen Adressbuchs im jeweils anderen ebenfalls vorzunehmen oder verschreiben Sie sich dabei, dann weichen die Datenbestände der beiden Adressbücher voneinander ab. Die Daten sind dann insgesamt inkonsistent. Jede Aufgabenstellung erfordert bestimmte Datenstrukturen, wie beispielsweise das Suchen und Finden von Vor- oder Nachnamen. Ändert sich die Aufgabenstellung, wie zum Beispiel die Suche nach Personen, die in einem bestimmten Ort wohnen, so müssen andere Datenstrukturen genutzt werden, was wiederum zu einer Mehrfachspeicherung führt, die mit Mehraufwand und der potentiellen Gefahr von Fehlern verbunden ist, wenn Sie diesem Drang mit einem weiteren Adressbuch nachgeben.
Relationales Datenbankmodell
Es gibt verschiedene Datenbankmodelle. Das verbreitetste Datenbankmodell ist das relationale Datenbankmodell. Es geht auf E.F. Codd (vgl. https://de.wikipedia.org/wiki/Edgar_F._Codd) zurück, einem Mathematiker, der einst in den Diensten der Firma IBM stand. Das Modell basiert auf den mathematischen Grundlagen der Relationenalgebra. Demzufolge mögen die verwendeten Begriffe, die das Modell beschreiben, gewöhnungsbedürftig sein.
Eine logisch zusammenhängende Menge von Objekten wird in einer 2-dimensionalen Matrix erfasst. Der Volksmund spricht von einer Tabelle. Tabellen bestehen aus Zeilen (Datensätzen) und Spalten (Attributen). Letztere werden auch als Felder oder Eigenschaften bezeichnet. Um eindeutig auf einen Datensatz zugreifen zu können, wird eine Spalte oder auch eine Spaltenkombination benötigt, deren Inhalt frei von Redundanzen ist, also garantiert nicht mehrfach vorkommt. Andernfalls wären die Datensätze anhand dieses Kriteriums, den Werten dieser Spalte oder dieser Spaltenkombination, nicht unterscheidbar.
Schlüssel
Eindeutige Spalten oder Spaltenkombinationen heißen Identifikationsschlüssel. Sie werden oftmals auch Primärschlüssel genannt. Identifikationsschlüssel müssen in jeder Zeile einen validen Wert besitzen und für jede Zeile einmalig sein. Es gibt Tabellen, bei denen für diese Aufgabe mehrere Spalten und/oder Spaltenkombinationen geeignet sind. Diese heißen Kandidatenschlüssel, weil sie mögliche Kandidaten darstellen, einen Identifikationsschlüssel für eine Tabelle zu definieren. Kandidatenschlüssel sind häufig Zahlenwerte oder Zahl-Text-Kombinationen, wie beispielsweise Artikelnummern, Personalnummern oder ähnliches.
Einige Tabellen enthalten Spalten oder Spaltenkombinationen, deren Inhalte eine (eventuell unechte) Teilmenge der Identifikationsschlüssel einer anderen Tabelle darstellen. Das sind sogenannte Fremdschlüssel. Sie verweisen auf den Identifikationsschlüssel einer anderen Tabelle. Zum Beispiel sind alle Mitarbeiter eines Unternehmens durch eine Personalnummer eindeutig identifiziert. Gleiches gilt für Projekte, die eine Projektnummer besitzen. In einer Tabelle, die Projektbeteiligte darstellt, werden sowohl Projektnummern als auch Personalnummern notiert, um die entsprechende Zuordnung abzubilden. Personalnummer und Projektnummer sind in dieser Zuordnungstabelle Fremdschlüssel, welche auf die entsprechenden Identifikationsschlüssel in der Personal- beziehungsweise Projekttabelle verweisen.
Selektion, Projektion
Die Tabellen eines relationalen Datenbankmodells können mithilfe mathematischer Verfahren bearbeitet werden. Sie können sowohl eine Teilmenge in Bezug auf die vorhandenen Zeilen auswählen (Selektion) und/oder eine Teilmenge bezüglich der vorhandenen Spalten (Projektion).
Referentielle Integrität
Das relationale Grundkonzept sieht keine festen Verbindungen zwischen Tabellen vor. Die Beziehungen werden durch die Abfrage bestimmt und haben temporären Charakter. Ungeachtet dessen bieten aktuelle Datenbankmanagementsysteme fast durchgängig das Feature der referentiellen Integrität, um Fremdschlüsselverweise zu unterbinden, die mangels fehlender Identifikationsschlüssel nicht aufgelöst werden können. Betrachten wir die folgenden zwei Tabellen, kunden und konten. Sie sollen die vereinfachte Beziehung zwischen den Kunden einer Bank und deren aktuellen Kontoständen abbilden.
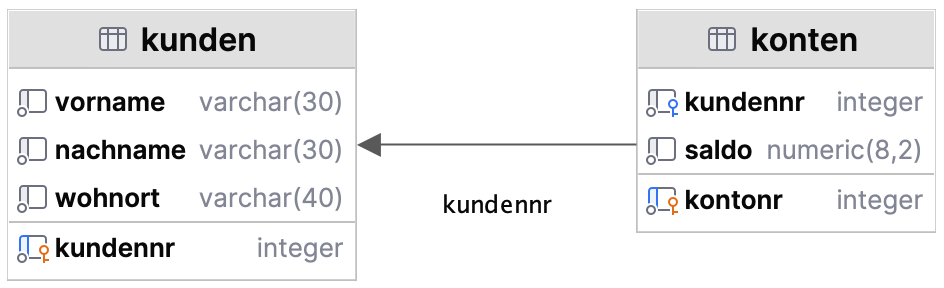
Das Attribut kundennr in der Tabelle kunden ist der Identifikationsschlüssel dieser Tabelle. In der Tabelle konten ist die Kontonummer (kontonr) der Primärschlüssel. Die Kundennummer ist hier ein Fremdschlüssel, der auf die Kundentabelle verweist. Ein Kunde kann mehrere Konten innehaben. Dieser Sachverhalt kann hier an der Verbindungslinie zwischen den Tabellen leider nicht direkt abgelesen werden. – Ich habe diese Abbildung mit DataGrip von JetBrains erstellt. Andere Werkzeuge, wie beispielsweise die Workbench von MySQL gestalten derartige Abbildungen, die sich übrigens ER-Diagramme (Entity Relationship Diagram) nennen, etwas leichter lesbar.
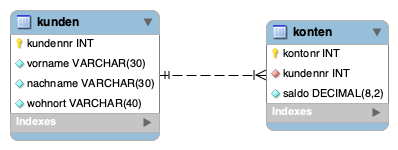
Hier steht der Doppelstrich auf Seiten der Kundentabelle für die Kardinalität 1, der Krähenfuß auf der Seite der Kontentabelle steht für n. Wir haben hier eine sogenannte 1:n-Beziehung. Ein Kunde kann n Konten besitzen, jedes Konto gehört genau einem Kunden. Die Diagramme stellen jeweils den gleichen Sachverhalt dar. Die Art der Darstellung ist jedoch voneinander abweichend. Weil die Kundennummer in der Kundentabelle der Primärschlüssel und in der Kontentabelle ein Fremdschlüssel ist, der dort keinen Datensatz eindeutig identifiziert, ist jedoch auch aus der mit DataGrip erstellten Abbildung eindeutig eine 1:n-Beziehung erkennbar. Man muss jedoch etwas genauer hinschauen, um den Sachverhalt zu erkennen.
Projektion und Selektion
kundennr |
vorname |
nachname |
wohnort |
|---|---|---|---|
| 1000 | Peter | Meier | Osnabrück |
| 1001 | Peter | Meier | Hasbergen |
| 1002 | Sabine | Schulze | Osnabrück |
| 1003 | Patrick | Schwarzer | Osnabrück |
| 1004 | Susanne | Maier | Georgsmarienhütte |
kontonr |
kundennr |
saldo |
|---|---|---|
| 12345678 | 1000 | 2,000.00 |
| 12345679 | 1001 | 2,500.00 |
| 12345680 | 1002 | 1,000.00 |
| 12345681 | 1003 | 2,100.00 |
| 12345682 | 1004 | 3,000.00 |
| 12345683 | 1004 | -500.00 |
Eine mögliche Projektion der Tabelle kunden stellt die Frage nach den Vor- und Nachnamen aller Bankkunden.
vorname |
nachname |
|---|---|
| Peter | Meier |
| Peter | Meier |
| Sabine | Schulze |
| Patrick | Schwarzer |
| Susanne | Maier |
Der Name „Peter Meier“ wird doppelt ausgegeben. Daran erkennen Sie bereits, dass Namen selten gute Identifikationsschlüssel sind. Die Ausgabe aller Datensätze, bei welchen die Person in Osnabrück wohnhaft ist, ist eine Selektion.
kundennr |
vorname |
nachname |
wohnort |
|---|---|---|---|
| 1000 | Peter | Meier | Osnabrück |
| 1002 | Sabine | Schulze | Osnabrück |
| 1003 | Patrick | Schwarzer | Osnabrück |
Projektion und Selektion sind miteinander kombinierbar.
vorname |
nachname |
wohnort |
|---|---|---|
| Peter | Meier | Osnabrück |
| Sabine | Schulze | Osnabrück |
| Patrick | Schwarzer | Osnabrück |
Relationenbildung
Fragt eine Abfrage nach tabellenübergreifenden Attributen, so werden die Tabellen mittels einer mathematischen Verknüpfung (kartesisches Produkt) für die Dauer der Abfrage miteinander verbunden. In der Regel geschieht dies auf Basis wertgleicher Merkmale. Diese „gezielte Redundanz“ in der Speicherung von Merkmalsausprägungen sollte die einzige Mehrfachspeicherung innerhalb einer Datenbank sein. Eine solche Tabellenverknüpfung heißt Relationenbildung. Wir sprechen auch von sogenannten Joins.
kundennr |
vorname |
nachname |
wohnort |
kontonr |
saldo |
|---|---|---|---|---|---|
| 1000 | Peter | Meier | Osnabrück | 12345678 | 2,000.00 |
| 1001 | Peter | Meier | Hasbergen | 12345679 | 2,500.00 |
| 1002 | Sabine | Schulze | Osnabrück | 12345680 | 1,000.00 |
| 1003 | Patrick | Schwarzer | Osnabrück | 12345681 | 2,100.00 |
| 1004 | Susanne | Maier | Georgsmarienhütte | 12345682 | 3,000.00 |
| 1004 | Susanne | Maier | Georgsmarienhütte | 12345683 | -500.00 |
Auch auf eine Relation sind Selektionen und Projektionen anwendbar, wie beispielsweise die Konteninformation aller in Osnabrück wohnhaften Kunden.
kundennr |
vorname |
nachname |
kontonr |
saldo |
|---|---|---|---|---|
| 1000 | Peter | Meier | 12345678 | 2,000.00 |
| 1002 | Sabine | Schulze | 12345680 | 1,000.00 |
| 1003 | Patrick | Schwarzer | 12345681 | 2,100.00 |